This is the full write-up on our experiment with Gábor Madarász.
Digitizing books is a longstanding problem in the NLP field. It is an even harder problem in low-resource language such as Hungarian. We have tested in a short experiment how far the latest generation of Qwen models (3rd generation) has come. We will first introduce the documents we have selected and the idea behind every choice. After this we will show the results.

Method
We have used a diverse set of images, although a small set, to evaluate Qwen3 Instruct VLMs. From the versions we only tried out the smaller ones that can be run on consumer hardware (2B, 4B and 8B). We have used tesseract with docling as a baseline. We have prepared a gold-standard human annotated version of the texts. Our aim is digitizing valuable texts from the past that convey our culture and knowledge and not only make it readable to humans but to make them searchable for programs too.
The texts
A poem – text-1

We have chosen this text because of the punctuation marks and the unique ordering of words. We wanted to test how well the models can generalize to texts. Glyphs in this text are very close, and it is hard to find the border of each character. This text proved to be a piece of cake for all methods mentioned.
History of law book – text-2

This text has the old traditions of em-dash use inside the Hungarian quotation marks. This document uses old language and now unused versions like “eme” – this, and various low use, technical language. As you can see the page is yellowed by age and the picture itself is not aligned to normalize (it is made in an angle). Also in the footnotes you can see, that the book it references is in German, so the models have to incorporate more languages in the same text.
A listing of books in two columns – text-3

This was one of the most challenging texts. Most methods despise columns and columns continuing from the other side. An added difficulty was the old names and the font choice of the publisher. The page is very aged, the photo was taken then it was wrinkled. Also the text is a bit blurry, making it a harder challenge.
A page from a linguistics book – text-4

This text contained a lot of special characters – many of them fooled the systems. The main texts were mostly perfect for all, but the examples could really mess with how the signs were interpreted.
Psycholinguistics paper page – text-5

This paper was interesting because it contains utterances from people with Aphasia. The symptoms of aphasia contains, well depending on the type, non existent words or existing words in nonsensical order. This proved to be a real difficulty even for humans to transcribe, but this text was the hardest test for the models.
Results
We have employed Character level, Word level error rates as well as ROUGE-L scoring.
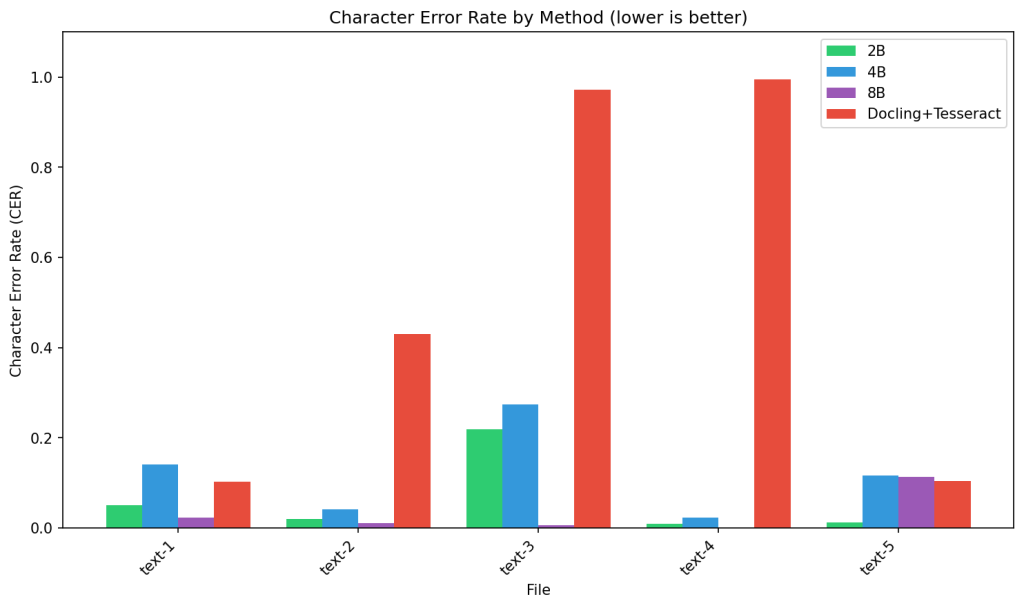
Character Error Rate (CER) measures the proportion of character-level edits needed to match the reference text. The 8B model achieves consistently low error rates (0.02-0.11), while Docling+Tesseract catastrophically fails on text-3 and text-4 (CER ~1.0), mostly because it treated figures as images and skipped them. Surprisingly, the 4B model occasionally underperforms the 2B variant, indicating that model scaling alone doesn’t guarantee better performance for specialized Old Hungarian script conversion.
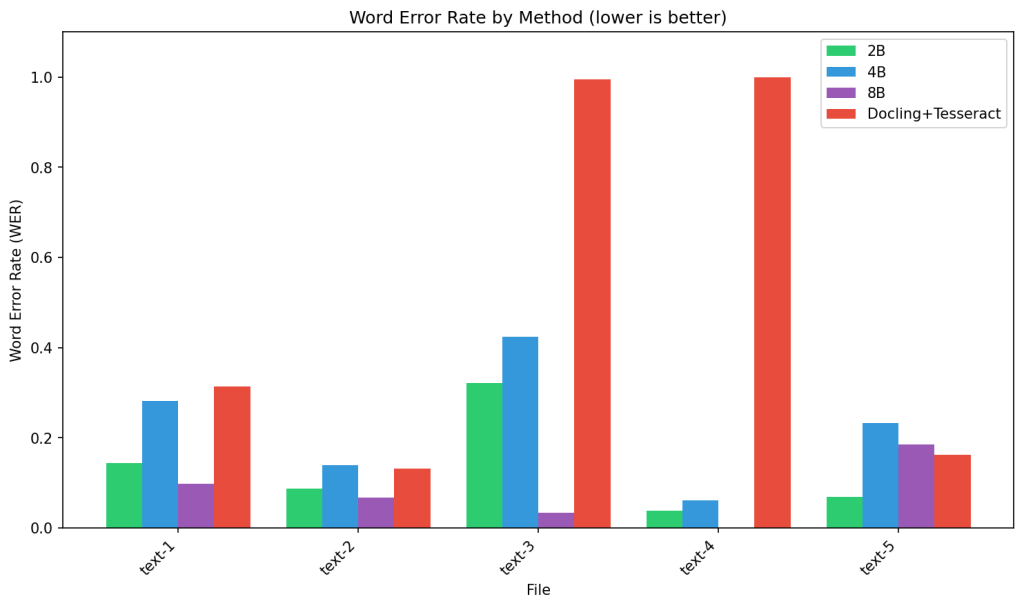
Word Error Rate (WER) evaluates word-level accuracy and shows similar patterns, with 8B leading at 0.03-0.18 error rates. Notably, WER consistently exceeds CER across all models, revealing that while character recognition may be accurate, assembling complete words remains challenging. This gap is most pronounced in smaller models, suggesting that word-level context understanding benefits significantly from increased model capacity.
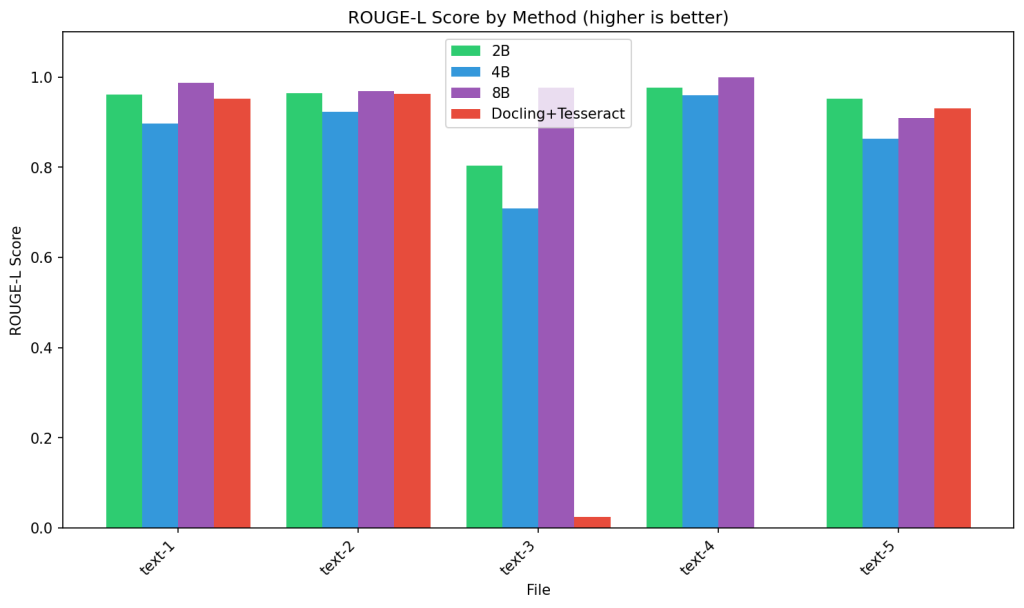
ROUGE-L Score measures structural similarity through longest common sub-sequence matching. The 8B model maintains scores above 0.90, demonstrating strong sequence preservation. Docling+Tesseract’s near-zero score on text-3 (~0.02) while performing reasonably elsewhere indicates this file contains particularly challenging visual elements. The incomplete predictions visible for some model-file combinations correlate with the perfect error rates in CER/WER, suggesting complete failure on certain texts.
All in all
We see the superiority of the 8B model and a great performance from the 2B variant. Both are very close to human levels.
Alas, not just accuracy is at stake when processing large amount of data, but a careful optimization of accuracy and speed. As you could see the 2B model was quite close to the 8B model on our test set. Using an RTX 5090 GPU the generation speed difference is dramatic (75 token/sec for 8B and 195 token/sec for 2B) and if we utilize parallelization we can even push to a 310 tokens/sec using the 2B model. In the end we have chosen the 2B model because it will yield the fastest, but still reliably good results.
Thank you for reading through!